MLOps Services — From ML Experiments to Production-Grade Pipelines
We design, deploy, and manage MLOps infrastructure so your models ship faster, scale reliably, and stay performant in production.
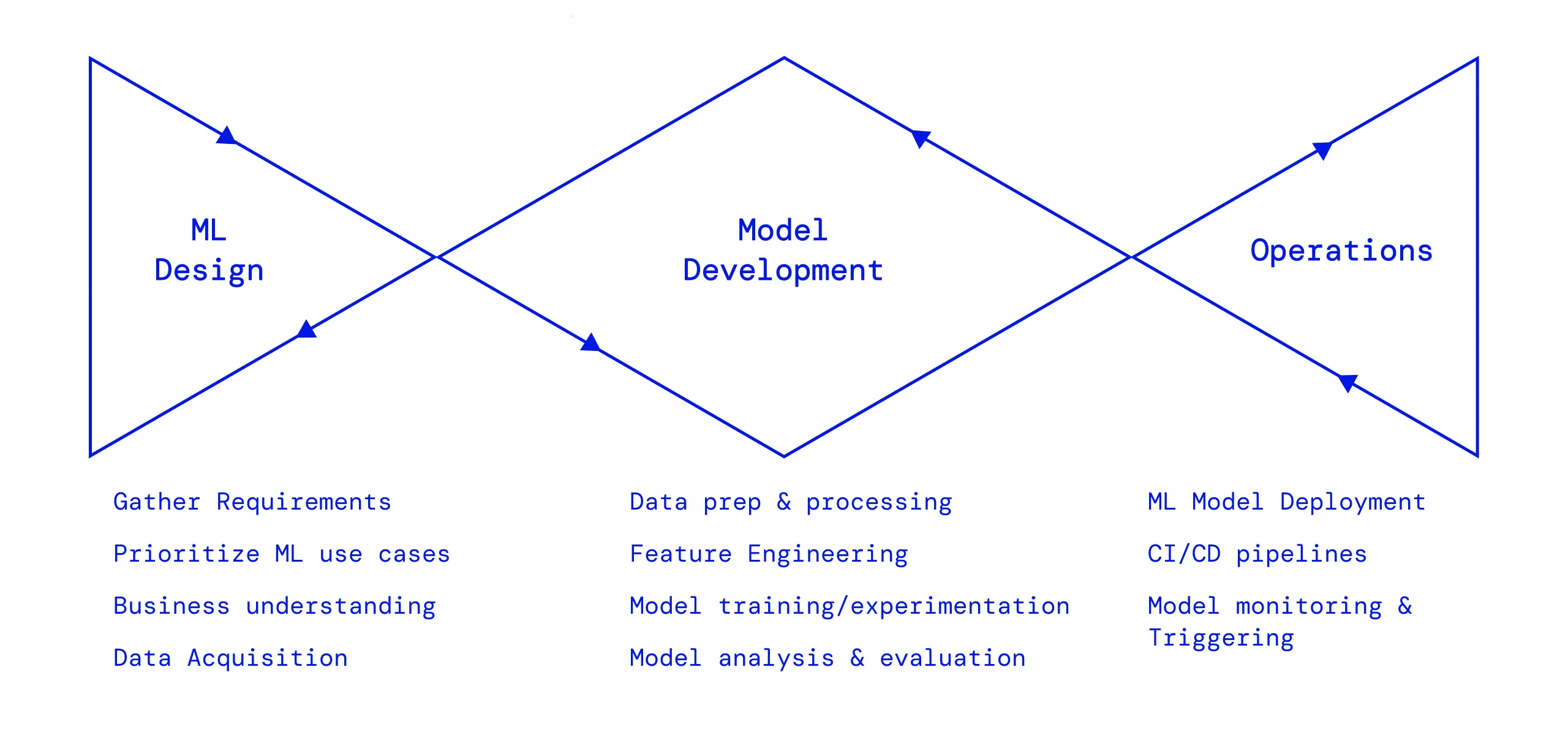
What is MLOps?
MLOps (Machine Learning Operations) bridges the gap between ML development and production deployment. It combines machine learning, DevOps, and data engineering to streamline the ML lifecycle.
MLOps ensures your models are:
- Deployed reliably and at scale
- Monitored and maintained continuously
- Reproducible and version-controlled
- Automatically retrained and updated

Core MLOps services
Comprehensive MLOps solutions to accelerate your machine learning initiatives.
MLOps assessment and strategy
Evaluate and optimize your ML development and deployment processes. Identify gaps in the ML lifecycle management and develop a tailored MLOps implementation plan.
ML pipeline automation
Design and implement end-to-end automated ML pipelines. Automate data preprocessing, feature engineering, model training and set up continuous integration for ML models.
Model versioning and experiment tracking
Implement version control and experiment tracking for ML models. Set up experiment tracking and management systems to enable reproducibility of ML experiments.
Model deployment and serving
Automate and scale model deployment processes. Implement scalable model serving solutions and set up A/B testing and canary deployments for ML models.
ML development
Custom ML model development and optimization. ML Model Optimization and ML Model Integration, Training & Validation for your specific business needs.
Why companies choose us
Expert MLOps services that help you build scalable and reliable ML systems in production.
End to end automation
We automate the entire ML lifecycle from data ingestion to model deployment and monitoring.
Scalable infrastructure
Our solutions scale with your business needs and handle increasing data volumes.
Continuous monitoring
Real-time monitoring and alerting to ensure your models perform optimally in production.
Industry expertise
Deep expertise across industries with proven MLOps implementations.
Faster time to market
Accelerate your ML project delivery with proven frameworks and best practices.
Cost optimization
Optimize infrastructure costs while maintaining high performance and reliability.
Advantages of adopting MLOps
Unlock the full potential for your machine learning system
Automated pipeline
Streamlined machine learning pipelines automate data preprocessing, model training, and deployment processes, significantly reducing manual intervention and errors.
Model monitoring
Continuous tracking of model performance and data drift ensures AI systems maintain accuracy and reliability in production environments.
Version control
Systematic tracking of datasets, model parameters, and code versions enables reproducible experiments and efficient collaboration among data scientists.
Scalable infrastructure
Dynamic resource allocation and containerized environments support efficient model training and serving across different computing infrastructures.
Data governance
Automated data validation, lineage tracking, and quality checks ensure models are trained on reliable, consistent, and compliant datasets.
Continuous training
Automated retraining pipelines keep models updated with fresh data, maintaining optimal performance and adapting to changing patterns.
Take Your ML Models from Notebook to Production
Our MLOps engineers design and deploy automated pipelines, monitoring systems, and CI/CD workflows that keep your models performant, reproducible, and cost-efficient at scale.