Eliminate uncertainty in your AI development lifecycle
Quantify the performance of your LLMs, RAG systems, and Agents. Our rigorous evaluation framework ensures your AI solutions meet enterprise standards for accuracy and reliability.
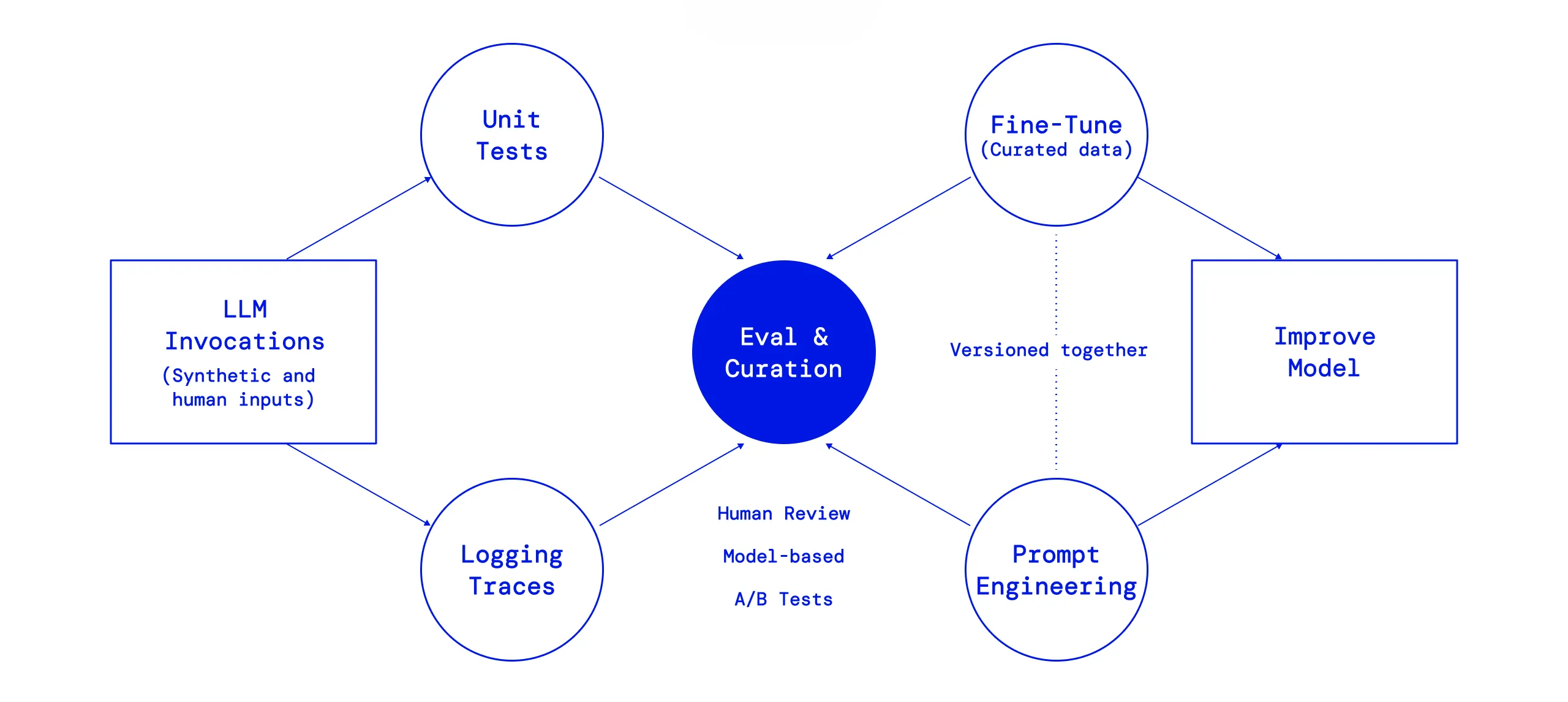
Custom evaluation frameworks
Every AI architecture demands a unique validation strategy. We move beyond generic benchmarks to stress-test your specific models and RAG pipelines against your real-world data and custom performance requirements.
Why evals matter
AI models don’t just fail when they’re inaccurate. They fail when:
Datasets are mislabeled or biased
Models hallucinate or produce unsafe content
Edge cases and adversarial prompts go untested
Evals as a Service ensures your AI is trustworthy, robust, and aligned — before it reaches production.
25k+
Happy Clients



469k
Social followers
The evaluation journey
Enterprise grade validation without the engineering overhead You shouldn’t have to divert your core team to build complex internal benchmarking tools. We provide the infrastructure, the expertise, and the objective analysis, combining high-speed automated judging with expert human oversight to deliver decision-ready insights.
Scenario definition & data integration
Define your objectives. We begin by identifying the specific components of your stack you wish to validate—whether it is a complex RAG pipeline, multi-step autonomous agents, or a side-by-side comparison of foundation models.
- The Input: You provide your target workflows, representative user queries, and any existing "Golden Sets" (ground-truth data).
- The Goal: We ensure the evaluation framework is perfectly aligned with your actual production environment.
Calibrated review & methodology selection
Customize your level of rigor. Accuracy requirements vary by use case. We offer a tiered approach to validation so you can balance speed with precision.
- LLM-as-a-Judge: Rapid, scalable scoring using advanced, proprietary evaluation prompts to detect hallucinations and relevance at scale.
- Expert Human Review: High-fidelity manual auditing for nuanced tasks where human judgment, empathy, and specialized domain knowledge are non-negotiable.
- Hybrid Validation: The gold standard automated broad-spectrum testing verified by human-in-the-loop spot checks.
Decision ready reporting & strategy
Identify the clear winner. We move beyond raw data to provide a comprehensive Evaluation Report that translates metrics into action.
- The Output: A clear, comparative analysis that identifies which model, prompt, or retrieval strategy outperformed the rest.
- Strategic Support: We don’t just hand over a spreadsheet; we provide a post-evaluation consultation to help you interpret the results and optimize your next deployment phase.
Industries we serve
Precision-engineered evaluations for high-stakes environments. We translate complex industry requirements into objective benchmarks, ensuring your AI solutions meet the specific safety, accuracy, and compliance standards of your sector.
Know exactly how your AI performs before you ship
We build custom eval frameworks for your models, RAG pipelines, and agents — combining automated judging with expert human review to give you decision-ready performance insights